Reconocimiento de Dígitos Hablados
El reconocimiento de la escritura personalizada por parte de la interfaz de un dispositivo sería un gran avance en la interacción hombre máquina, como se discutió en el apartado de Reconocimiento de Caracteres Escritos.
El siguiente gran paso sería el reconocimiento de la voz humana, de forma que la máquina pudiera entender directamente órdenes habladas. Sin ser tan ambiciosos, y más acorde a los modestos avances que se han logrado en este campo, hemos creado un applet que es capaz de reconocer los diez dígitos a partir de los espectros en frecuencia que generamos cuando los pronunciamos.
La interfaz simula un locutor automático como el que algunas compañías telefónicas están usando ya hoy en día.
La base de funcionamiento no difiere mucho de la que hemos visto en el Reconocimiento de Disparos:
Realizamos distintos ejemplos de prueba y ensayo, tomando distintos sujetos que pronuncien los dígitos. Se tomarán sujetos de distinto sexo, edad y procedencia para que el conjunto de ejemplos resultante sea lo más general posible.
Se procesan los ejemplos para obtener entradas adecuadas para la red. Más abajo se explica esta fase en detenimiento.
Se muestran a la red algunos de los ejemplos, para que los aprenda. El resto se guardan para realizar pruebas.
Cuando la red ha aprendido se observa su funcionamiento con los ejemplo de prueba, comprobando su efectividad y capacidad de generalización.
Si el paso cuatro ha sido satisfactorio, congelamos los pesos obteniendo así una aplicación que soluciona el problema. Cualquier nueva entrada, debidamente procesada, deberá ser reconocida por la red.
Quiero agradecer a mi tutor Luis Alonso Romero y a Ángel Luis Sánchez Lázaro, del Departamento de Informática y Automática de la Universidad de Salamanca, la facilitación de juegos de entrenamiento excelentemente elaborados para la realización de esta aplicación.
PROCESAMIENTO DE SEÑALES DE VOZ
El análisis de la señal de voz recibida y su transformación hasta convertirse en entrada de la red neuronal es un proceso básico para que podamos reconocer los dígitos pronunciados.
Muestreo en amplitud
Al hablar por un micrófono, éste toma muestras de la amplitud de la señal sonora. Las muestras se toman a una velocidad medida en muestras por segundo (mps) denominada frecuencia de muestreo. Las señales de los ejemplos se toman a una frecuencia de muestreo de 11 Kmps.
Los micrófonos ofrecen varias opciones aparte de la frecuencia de muestreo. Se puede decidir si grabaremos sonido mono o estéreo, el tipo de modulación que usaremos y el número de bits que tomaremos para representar cada muestra.
En nuestro ejemplo, tomamos la siguiente configuración:
11025 muestras por segundo
Modulación PCM con signo
8 bits por muestra (255 valores)
Mono
Esta configuración devolverá un vector con valores en el intervalo [-127,128] siendo 0 el valor del silencio y el resto distintos grados de intensidad. 11025 valores corresponderán a un segundo de grabación.
Si representamos este vector como una función en el tiempo, obtendremos una forma de onda. La forma de onda resultante de este muestreo inicial tiene una forma similar a éstas:
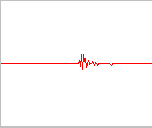
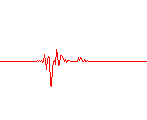
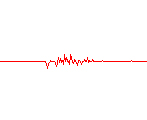
uno seis nueve
Como podemos ver, es difícil determinar qué palabra se ha dicho examinando a simple vista estas formas de onda. Por ello es necesario realizar un análisis frecuencial de la misma. Pero antes es necesario solucionar otro problema: ¿qué consideramos palabra y qué silencio o ruido ambiente?
Limitación de palabras:
Para ello se realiza un análisis energético y un estudio de cruces por cero. Consiste en dividir el vector anterior en pequeños intervalos temporales superpuestos (ventanas) y en analizar las diferencias entre los valores de las zonas sonoras y las de silencio. Los valores que se comparan son la energía (el valor absoluto de la amplitud al cuadrado) y los cruces por cero (número de veces que cambia de signo la función en cada ventana). No entraremos en mayor detalle sobre este paso.
Análisis frecuencial:
Una vez limitada la palabra, podemos realizar el análisis frecuencial. Se ha descubierto que el oído humano realiza este mismo análisis mediante uno de sus componentes, la cóclea. El análisis consiste en aplicar la Transformada Discreta de Fourier (DFT) a la forma de onda dividida en ventanas, para tener así no sólo una relación bidimensional tiempo-amplitud sino una tridimensional de tiempo-frecuencia-energía. Este paso se implementa mediante Transformadas Rápidas de Fourier (FFT), que reducen considerablemente el tiempo de computación de la DFT.
El resultado del análisis frecuencial es el espectrograma. Aquí vemos los espectrogramas correspondientes a las anteriores formas de onda. El eje de abscisas corresponde al tiempo y el de coordenadas a la frecuencia. La tonalidad de gris indica la energía en cada punto, siendo el negro lo más energético:



uno seis nueve
Como vemos ahora se distingue mucho más claramente cada palabra. Prácticamente cada fonema es distinguible del resto. Por ejemplo, las oclusivas apenas tienen energía en ninguna frecuencia, las fricativas tienen bastante energía en frecuencias altas, etc.
El espectrograma es la base de la entrada a nuestra red neuronal, tan sólo es necesario discretizarlo para disminuir el número de neuronas de entrada necesarias.
Compresión temporal:
Mediante medias aritméticas simples, reducimos las muestras a ocho intervalos de tiempos
Compresión frecuencial:
El oído humano es sensible de distinta manera a cada frecuencia, siguiendo una escala cuasi-logarítmica debido a la forma en espiral de la cóclea. Esto lo recogen las bandas de Mel, dividiendo las frecuencias de 0 a 5 KHz en zonas más amplias cuanto más altas en frecuencia. Usando 16 bandas, obtendremos 16 valores de frecuencia para cada intervalo temporal.
Con esto, cada palabra quedará representada por 16 valores de energía en cada intervalo temporal, haciendo un total de 128 valores, que condiciona el número de entradas de nuestra red neuronal.
Aquí vemos cómo quedan los espectrogramas discretizados:



uno seis nueve
ARQUITECTURA
La arquitectura como en otros casos se adapta a las necesidades del problema:
128 neuronas de entrada, que son los intervalos de tiempo en que discretizamos el espectrograma.
10 neuronas de salida, una por cada dígito del 0 al 9.
El número de neuronas ocultas permanece configurable. Por defecto usaremos 16 neuronas, un número que se ha probado suficiente para obtener una respuesta satisfactoria de la red.
ENTRENAMIENTO
El esquema de entrenamiento de esta aplicación es idéntico al que hemos utilizado para el resto de las aplicaciones del perceptrón multicapa. Como en otros casos, obtener un error muy pequeño para la red puede resultar una labor tediosa, pues llega un momento en que la red aprende muy lentamente. Para ello, ofrecemos el botón cargar Pesos que proporciona pesos congelados para un error cuadrático medio de 5.2. Aunque pueda parecer un error muy alto, lo cierto es que da casi un 100% de efectividad en los ejemplos de prueba.
El entrenamiento puede resultar también un proceso lento ya que utilizamos 800 patrones de ensayo, muestras tomadas de la pronunciación de los diez dígitos por diez hablantes distintos, tanto hombres como mujeres de distintas edades. Tenemos ocho pronunciaciones por hablante y por dígito. Otras dos pronunciaciones por hablante y dígito se guardan para el conjunto de prueba.
Según la fórmula empírica de Baum, podemos obtener un error mínimo de: número de pesos de la red / número de patrones de entrenamiento
En el caso por defecto será (128x16 + 16x10) / 800 = 2'8.
EJECUCIÓN
Mediante el cuadro de selección de la izquierda podemos elegir qué dígito usar como entrada de prueba a la red. Cuando pulsamos Hablar la red toma una entrada aleatoria de las 20 correspondientes a ese dígito que reservamos como conjunto de prueba.
El teclado numérico que aparece debajo ilumina las teclas con más probabilidad de ser el dígito pronunciado. La tecla que aparezca en un verde más brillante es el dígito reconocido. Generalmente, si el entrenamiento es adecuado, sólo se ilumina una tecla verde. En algunos casos todas las teclas permanecen rojas. En ese caso, la letra roja más oscura sería la seleccionada por la red como candidata, aunque el hecho de tener dicha tonalidad en vez de verde indica que no está muy segura de su decisión (menos de un 50% de seguridad).
Al pulsar Hablar se escucha el número elegido. Cabe reseñar que es un efecto meramente estético: el sonido que oímos no se corresponde con la relación de frecuencias que se ofrecen a la red neuronal.
Hemos creado una versión especial de esta aplicación que permite al usuario introducir voz mediante un micrófono. Dicha aplicación tiene toda la funcionalidad de la que se ve en esta página más la grabación y reconocimiento de sonidos propios.
Debido a la política de seguridad de Java, la grabación de sonidos está deshabilitada para los applets a no ser que el usuario acepte voluntariamente activarla. En el siguiente enlace se le pedirá su autorización para instalar y ejecutar la aplicación. Dicha aplicación se encuentra firmada, distribuida y verificada por la Universidad de Salamanca. Pulse AQUÍ para acceder al programa